Hacking Wordle
Do you recently see something like this on twitter:Wordle 221 4/6
⬛⬛⬛⬛⬛
🟨🟨⬛⬛⬛
⬛⬛🟩🟩🟨
🟩🟩🟩🟩🟩These are the results from the online word game "wordle" which got some attention recently.
The game play is very simple: You have to guess a five character word. After each guess the game will give you hints:
- Characters that are not in the solution
- Characters that are in the solution but not at the position as in your guess
- Characters that are in the solution and at the right position of your guess.
With this hints you have to find the word in at most six tries.
Since I'm not a native (english) speaker - as you might noticed - I recognized that my vocabulary is pretty limited. So I decided to do a little bit of research on how to narrow the solution with code instead of my limited vocabulary.
The Idea
The idea is pretty simple:
- Find a list of english words with five letters
- Create a letter count for each letter index
- Create a score for each word how likely it could be the solution
- Filter the words with the hints from the wordle game to narrow the solution
so don't let's hesitate.
Find a Wordlist
If you search things like "n common englisch words .txt" you would probably find a lot. The only problem i had was that it could not be "in sync" with wordle. So I could end up with a suggestion that is not even possible in wordle. Wordle itself complains when you enter a guess that is "Not in word list" so I thought: This list must be either loaded via HTTP-Request or statically hardcoded in the JavaScript sources. Fortunately we have cool things like the devtools.
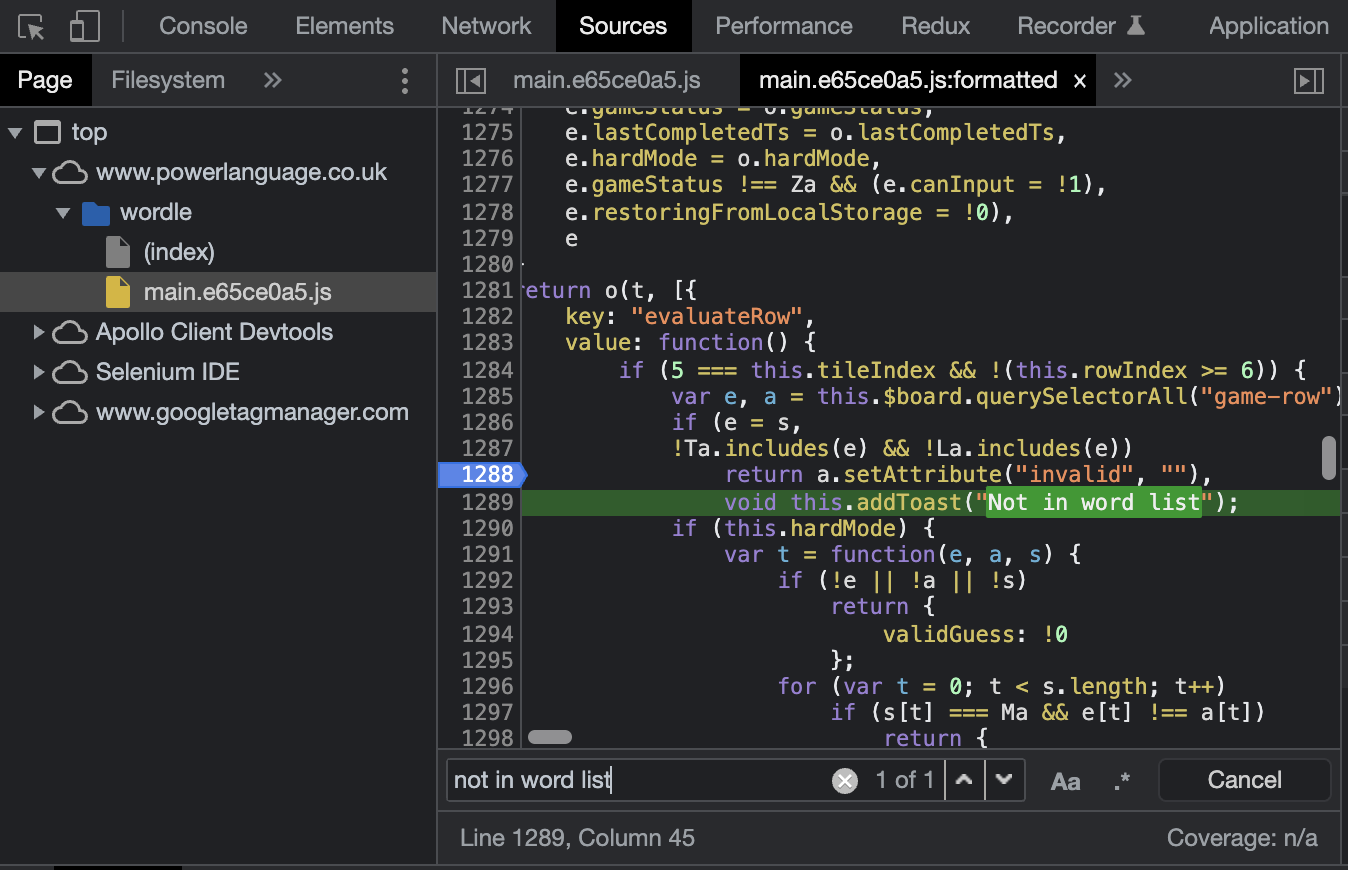
In the "source" tab in dev tools we can find a main.*.js file in which we
can search for "not in word list" (This message is shown in a popup when you
guess a word which is not in the wordlist). In the line before we can see a
condition statement which checks Ta or La includes e. You can set a
breakpoint there and enter some senseless guess ("abcde" e.g.) to make some
interesting observations:
eis the guess you madeTaandLaare list of words
So here we are and we have our word lists.... Wait! Way we found two lists? If you look closely two points are strinking:
- They have very different lengths (10657 vs. 2315)
- The larger list seems to be ordered (from a to z) while the second seems to be in random order
La[221]; // 'whack'So if you want, you could stop here and impress your follower everyday with:
Wordle n 1/6
🟩🟩🟩🟩🟩
(make sure not to retweet this post before 😉).
If you want to go further you could save the word into an .txt file. Just execute this snippet in the dev tools console when you hit the breakpoint
console.log(La.concat(Ta).join("\n"));Dev tools will offer you to copy the printed list so from that point it will be
easy to save it into words.txt.
Create a letter count
To process the word list I'm using python.
from collections import Counter
def get_lines(file: str):
with open(file, 'r') as file:
lines = file.readlines()
return lines
matrix = [list(word.strip()) for word in get_lines('words.txt')]
matrix_t = [list(word) for word in zip(*matrix)]
char_counts = [Counter(word) for word in matrix_t]In this snippet I first define a helper to read file contents as a string array.
Than we define a matrix which stores each word as an array of charaters. To
create a count for each character at each index we need a list of characters
per index or in other words the transposed from of matrix which we store
in matrix_t.
matrix [n_words x 5]
[
["a", "b", "c", "d", "e"],
["f", "g", "h", "i", "j"],
["k", "l", "m", "n", "o"],
["p", "q", "r", "s", "t"],
["u", "v", "w", "x", "y"],
// ...
];matrix_t [5 x n_words]
[
["a", "f", "k", "p", "u" /* ... */],
["b", "g", "l", "q", "v" /* ... */],
["c", "h", "m", "r", "w" /* ... */],
["d", "i", "n", "s", "x" /* ... */],
["e", "j", "o", "t", "y" /* ... */],
];So we can now iterate over matrix_t and apply pythons Counter class to the character list.
The Counter makes it easy to query some statistics:
char_counts[0].most_common(5)
# [('s', 1565), ('c', 922), ('b', 909), ('p', 859), ('t', 815)]In this example we can see that s is by far the most common starting letter
followed by c, b and so on.
Create a word score
With this counts we are able to create a very simple scoring model where we sum
up the count of each letter at its position.
Lets take the word whack (solution of wordle 221) as an example:
| Pos | Letter | Score |
|---|---|---|
| 0 | w | 413 |
| 1 | h | 546 |
| 2 | a | 1236 |
| 3 | c | 411 |
| 4 | k | 259 |
| Sum | 2865 |
So whack would have a score of 2865. With this model we can create a list of the "best words" to start:
| Score | Word |
|---|---|
| 11144 | sores |
| 11077 | sanes |
| 10961 | sales |
| 10910 | sones |
| 10794 | soles |
Of course there are plenty of improvements to the whole model.
Right now it doesn't consider the relation between single letters
(does words that starts with a s are likely to end with s or
more likely with another letter?).
Filter the word list
Now we have a list of words and can give each word a value, we should filter out the words that can definitely not be the solution based on the hints from wordle.

In the example above wordle tells us that we are searching for a word that:
- doesn't contain S and E (
ignore_chars) - definitely starts with H (
fixed_chars) - contains an O and an U but not at position two respectively three (
required_chars)
Lets start with the easy part and filter by the letters that are not in the word:
# assume word to be set by an iteration or function argument
ignore_chars = "se"
no_ignored_chars = all([c not in ignore_chars for c in word.lower()])For the other parts we define an input of a five character string where the position of the chars is important.
blank = " "
fixed_chars = "H "
matches_fixed_chars = all([ # check that all values are True
c == word[i] # check if the char is the same as in word at this position
for (i, c) in enumerate(fixed_chars) # get each char and its position
if c is not blank # ignore blanks
])The last constraint is a "little" bit trickier since it implies two requirements: A character must be in the word, but not at the certain position.
required_chars = " OU "
required_but_not_at = all([
c is not word[i] # evaluate that the char is not at that position in the word
for (i, c) in enumerate(required_chars) # get each char and its position
if c is not blank # ignore blanks
])
contains_requires = all([
c in word # evaluate that the char is in the word
for c in required_chars # just iterate over each char of the required chars
if c is not blank # you got the point ;)
])So we can finally compile all these constraints into a single function:
def word_is_allowed(word, ignore_chars=[], fixed_chars=" ", required_chars=" "):
ignore_chars = set(ignore_chars) - set(fixed_chars + required_chars)
no_ignored_chars = all([c not in ignore_chars for c in word])
matches_fixed_chars = all(
[c == word[i] for (i, c) in enumerate(fixed_chars) if c is not blank])
required_but_not_at = all([c is not word[i] for (
i, c) in enumerate(required_chars) if c is not blank])
contains_requires = all(
[c in word for c in required_chars if c is not blank])
return no_ignored_chars and matches_fixed_chars and required_but_not_at and contains_requiresFinally you can create a list that represents your guesses:
guesses = [
("se", "H ", " OU "),
("eady", " ", "R "), # Input was ready
]
filtered_words = words
for (ignore_chars, fixed_chars, required_chars) in guesses:
words = [
word for word in words
if word_is_allowed(ignore_chars, fixed_chars, required_chars)
]And finally we can apply the score and sort the results:
result = sorted([
(get_word_score(word), word)
for word in words
], key=lambda r: r[0], reverse=True)The Tool
Finally i created a little user interface to make this code accessible. So have fun.
Summary
If you have tested the tool for a while you might noticed that it is not a silver bullet to accurately find the correct word. One technical aspects might be that the scoring model itself is very simplistic. It can be refined by running n-gram analysis the see which is the most likely neighbor of a certain letter at a certain position. Another aspect is a bit more human: The legend says that the creator of wordle created the game for his partner as a one person project. So maybe at least one human eye might checked the list of correct words to be "common" and "guessable" enough which would set back a lot of technical considerations.
💬 Any thoughts (or bugs in the tool)? Feel free to share them in the Github discussion